
Welcome back to Perpetually Confused. Today’s post is going to be about the structure of the web applications that I’ve been building in my software engineering class. I am going to draw heavily from the excellent textbook Engineering Software as a Service: An Agile Approach using Cloud Computing. I highly recommend this book to anyone who is interested in learning about software engineering. As an added bonus it has two companion classes hosted on edX, CS169.1X, and CS169.2x.
An important theme of software engineering is the primacy of division of labor. Common logic should be captured in classes and methods, and an application should be composed of individual components that are highly efficient at their assigned tasks. Let’s talk briefly about how the web works again. I mentioned in my blog post about remembering state in rails apps that the internet primarily works through request-response cycles. Users –people that surf the web– generate requests by interacting with web sites through a web browser like Chrome, Safari, or Firefox. Web browsers are highly specialized software that are designed to create an appealing and useful user-interface for people who want to explore the web. Web browsers don’t need to worry about storing data, or routing data, all they need to think about is how to show it.
By contrast, there is another super-specialized application that lives in the internet called a server. Servers are designed to efficiently receive requests from web browsers and respond with the the information that the web browsers want. They can serve hundreds of thousands of people at a time. Of course, the internet doesn’t have to work like this, but it does because it is efficient to separate presenting information from serving information. This design is called the client-server model. An alternative to the client-server model is peer-to-peer architecture. In the client-server model, the server is a centralized application that serves many clients. By contrast, in the peer-to-peer architecture, every user hosts resources that can be used to distribute information in a decentralized way. If you are not a Puritan, you are probably familiar with the peer-to-peer architecture of Napster, Kazaa, LimeWire and more recently, Bit Torrent.

The point of this discussion is that when designing software, the engineer needs to be cognizant of the design choices she is using and make sure she is efficiently implementing the software. Through laborious trail and error, software engineers have identified certain design principles that are useful for solving problems. They call these principles design patterns. Design patterns are not specific to computer science, in fact, design patterns are just re-usable solutions for solving specific problems. Imagine you are building a bridge to cross a river. There are a couple of different designs that you could choose for the bridge: arch, beam, suspension, cable-stayed. Some are more expensive than others, and some can hold more weight. The job of an engineer is to figure out which design is the best fit for the environment.
Today, and in future posts I want to describe the design patterns that I used to craft the rotten potatoes app. But, to do that I need to be a little bit more precise about my description of client-server models. Most of the code that is written for a web page sits near the server side of the client-server model. For this class, we used a three-tier architecture for the server which is composed of the presentation tier, the logic tier, and the persistence tier. An important point that you probably intuited from my last statement is that the server is not a monolithic entity, it is a program composed of many smaller programs, each with hyper-specific duties.
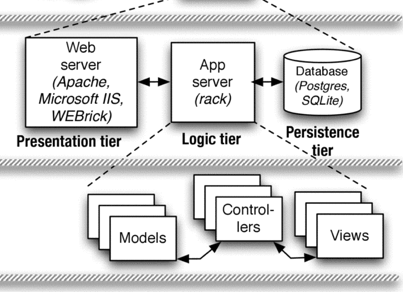
Before you can process any code on a website you need to deal with the requests from a client. The presentation tier is composed of the web server which is the part of the server that receives requests from clients. There is a built-in web server in ruby called WEBrick that performs this function. WEBrick is a pretty minimalist structure though, and it should not be relied upon to serve a web app in production. The web server routes traffic into the app server which understands how to respond to HTTP requests. The app server converts the HTTP request into a language that your web application speaks and hands it off to your code. Rails also has a built-in application server called Rack. The last component of the server is the persistence tier. The persistence tier is composed of a database. Databases store information that is important for the functioning of the web application, like user information. For the rotten potatoes app I am using the SQLite database.
That seems like enough anatomy today! I’ll be back shortly with a follow-up post on the Model-View-Controller design pattern and a brief discussion of Active Records in Rails!
